PLD+ - Accelerating LLM inference by leveraging Language Model Artifacts
Motivation
🤔 LLM inference is slow due to autoregressive token generation.
🤔 Speculative decoding accelerates inference by drafting & verifying tokens in parallel.
🤔 Limitations of speculative decoding - additional compute & fine-tuning requirements.
Observations
🎯 For many practical use-cases, LLMs reuse/build-on information from input context.

🎯 We have access to model internals (hidden states, attentions), computed during inference.
Research question: Can we speed up inference for input-guided tasks using these observations?
TLDR: Yes! Our tuning-free plug-and-play method PLD+ results in significant speedup for input-guided tasks and performs on-par/ outperforms SOTA tuning-dependent baseline.
No draft LLM model. No fine-tuning. Just faster decoding out-of-the-box.
What is PLD+?
PLD+ (Prompt Lookup Decoding Plus) is a speculative decoding technique for accelerating inference in input-guided tasks like code editing, summarization, etc. It improves upon prior string-matching approaches by leveraging model artifacts—namely, attentions from induction heads and hidden states from model layers—to identify optimal draft spans.
🧠 How Does It Work?
During decoding step t, PLD+ retrieves spans from the input where the last generated token xt-1 has occurred. These candidate spans are ranked based on either the:
-
Cosine similarity between hidden states of the token preceding the occurrence and the token preceding the last generated token (xt-2). (At time step t, we have access to hidden states of tokens only till xt-2, therefore we compare this hidden state with hidden state of the token preceding the occurrence)
-
Attention map from “induction heads” computed for token xt-1
Once ranked, the tokens following the occurrence with highest similarity/attention scores are proposed as the draft sequence (of length K tokens) and verified using the target model’s probability distribution.
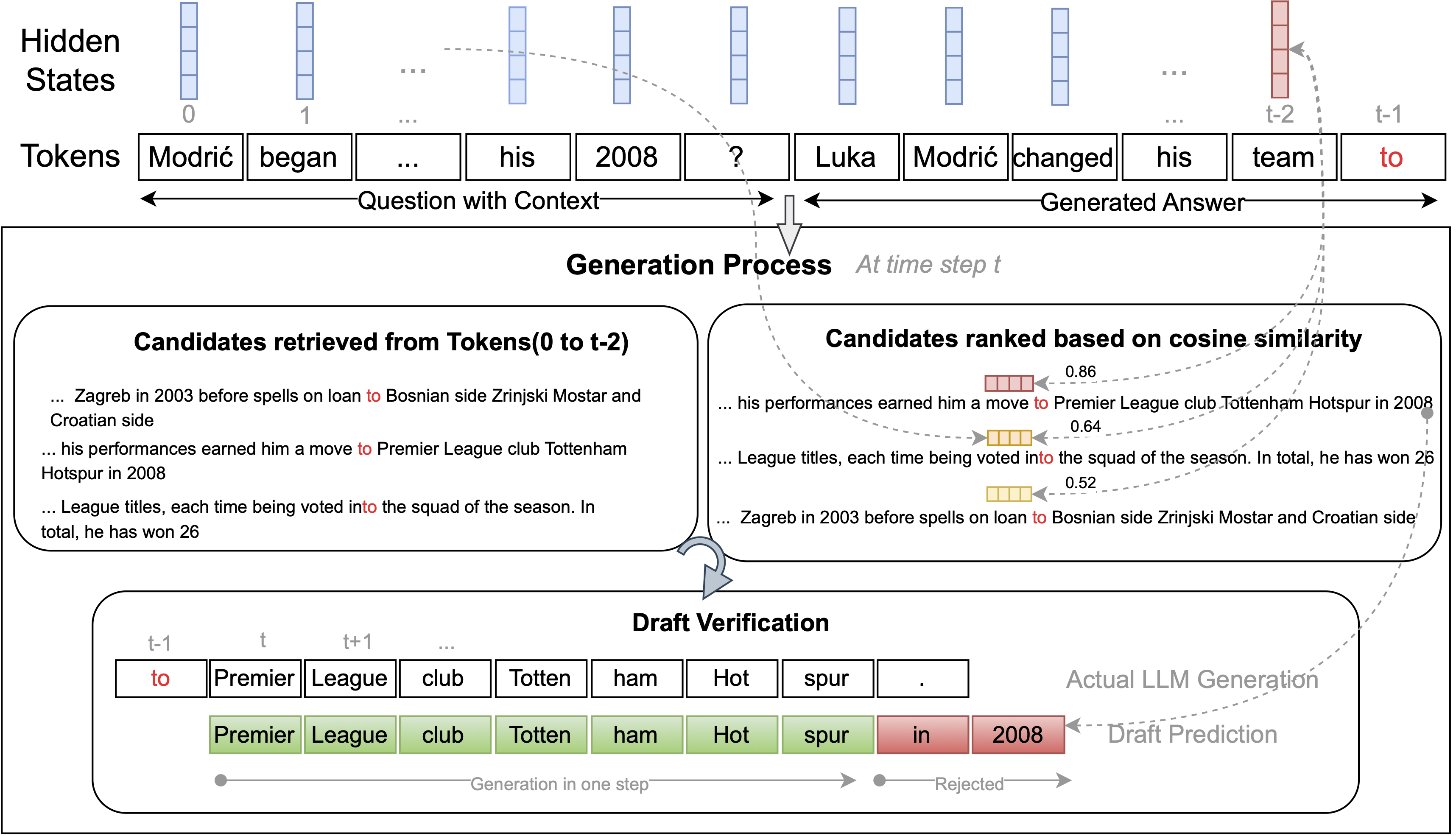
✅ Possible drafts are retrieved from context by searching for same tokens as token t-1 (“to”).
✅ Candidates are ranked using hidden states corresponding to token t-2 (“team”).
✅ The text following “to” in the highest ranked candidate is proposed as the draft
Algorithm for PLD+ (demonstrated with hidden states)

🧪 When Does It Work Best?
PLD+ excels in input-guided settings, where the output generation has high overlap with input context:
- Code editing
- Text editing
- Summarization
Not ideal for:
- Open-ended generation
- Tasks with low input-output overlap
🧠 Takeaways
- PLD+ speeds up decoding in a tuning-free, model-agnostic manner for input-guided tasks.
- It beats both heuristic (PLD) and fine-tuned (EAGLE) baselines on four input-guided tasks.
- PLD+ is plug-and-play and can be used to accelerate inferenec for any model. (Code to be shared soon!)